




Trends spurring the growth of machine learning (ML) for processing clinical and regulatory documentation include the increasing number and types of documents required by regulatory authorities, the availability of cloud software services, and a move toward greater data standardization. Modern-day cloud computing services offer a scalable means to store and process large libraries of documents. This is helping to boost ML performance, a function of the number of documents and types of documents used in developing an ML application. The industry’s gradual adoption of standards and reference models helps by providing more consistent terminology that ML can recognize as metadata.
In this article, we will discuss how combining the eTMF Exchange Mechanism Standard (EMS) with ML can improve TMF operations through more automated document transfer, classification and indexing.
Machine Learning and Trial Master File
ML is a branch of artificial intelligence (AI), a field that computerizes tasks that would otherwise require human intelligence. An ML application learns by processing examples of what it is being trained to analyze without relying on if/then statements typical of traditional computer programs (If condition x exists, then conclude y).
ML uses a neural network to train a machine to learn from experience. A neural network has a structure analogous to the network of neurons in a human brain. Processing units, or nodes, mimic natural neuron cells. Each node processes one or more input values and predicts an outcome based on its experience of processing similar inputs in earlier tasks. Each input value represents some characteristic, or feature, relevant to the task being performed. The network makes a single prediction for the task based on an overall assessment of the outcomes its nodes have predicted for different features of that task.
ML and AI have the potential to transform clinical trials by better understanding data within our documents, optimizing processes, and managing risk. For example, a pattern recognition network may identify a regulatory document as an FDA Form 1572. One feature of this form is the presence of an investigator signature on page 2. The network would learn to distinguish the placement of the signature by analyzing many examples of completed forms that have been manually labeled as “Form 1572” or “not Form 1572”. The processing logic recognizes the placement of the signature as an identifying characteristic of the form. This output combines with the outputs of nodes evaluating other document characteristics to determine whether a document is a Form 1572 or another type of document. It is the recognition of a combination of characteristics that lead to this conclusion, not a set of rules pre-coded as if/then statements (If the investigator signature is near the bottom of page 2 and other conditions are met, then the document is a Form 1572).
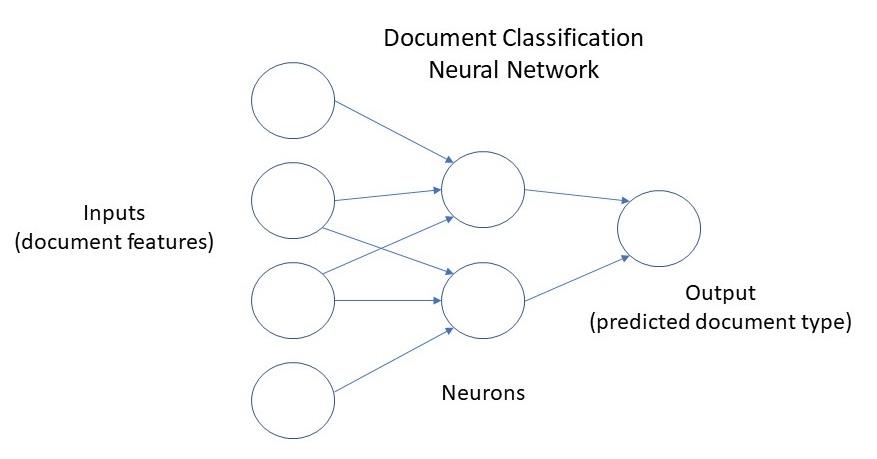
Another example involves using optical character recognition to extract metadata embedded in unstructured text. Metadata consists of attributes that describe a document, such as the study to which the document pertains. System users rely on metadata to locate documents in electronic TMF (eTMF) databases. A neural network can be trained to recognize an extracted attribute such as the name of a study and cross-reference it to an index that links the document containing it to the correct study.
ML promises to accelerate TMF filing processes. Manual entry is perhaps the most common way companies get metadata into eTMF systems. ML can reduce manual entry by automating the classification and indexing of TMF documents for filing. ML automation could also promote metadata standardization by reducing errors and increasing consistency. Resulting improvements in ensuring quality in TMF content would lead to fewer corrections and less rework. Developers of ML tools for TMF document classification and indexing have reported reductions in labor, acceleration in uploading documents, quality improvement and standardization.
To solve interoperability challenges, automating the sharing of data and documents across multiple systems could lead to shorter development timelines and approvals. Open standards like EMS could foster more seamless integration by specifying how documents should be delivered.

Machine Learning and the Exchange Mechanism Standard
The TMF Reference Model, created by volunteers under the auspices of the Drug Information Association (DIA), helps TMF stakeholders communicate TMF content and structure. The model suggests types of TMF documents, document names, and their identifiers. Vendors of eTMF systems provide templates based on the model that help users structure their TMFs. Companies are free to adapt the model to their own standards.
While possibly encouraging industry adoption, the Reference Model’s flexibility disregards problems in exchanging documents between computer systems. To transfer documents electronically, two companies using different metadata conventions must map the sending company’s metadata to that of the receiving company. Mapping consumes resources and time, involving project staff and sometimes taking many weeks. Some companies must map their eTMF metadata to multiple systems.
Resulting inefficiencies affect use cases such as transferring a final TMF from a CRO to a sponsor, transferring interim content to a central TMF, or migrating TMF content after an acquisition. Some companies automate the process partially by building custom interfaces. Many avoid transferring study documents until the end of a study, resulting in missing documents that regulatory inspectors may want to access during the study.
EMS extends the Reference Model. EMS provides a common protocol for exchanging documents and metadata between computer systems. The standard is vendor-agnostic and open to any developer for creating system interfaces. EMS reduces and may ultimately eliminate the need to map metadata or develop system interfaces for content exchange. It allows CROs to work in their own systems and transfer content to sponsors using the standard. The use of EMS can reduce backlogs in updating the TMF and reduce the risk of negative findings. Sponsors experience less disruption in inspection preparation, freeing them to focus more on managing trials.
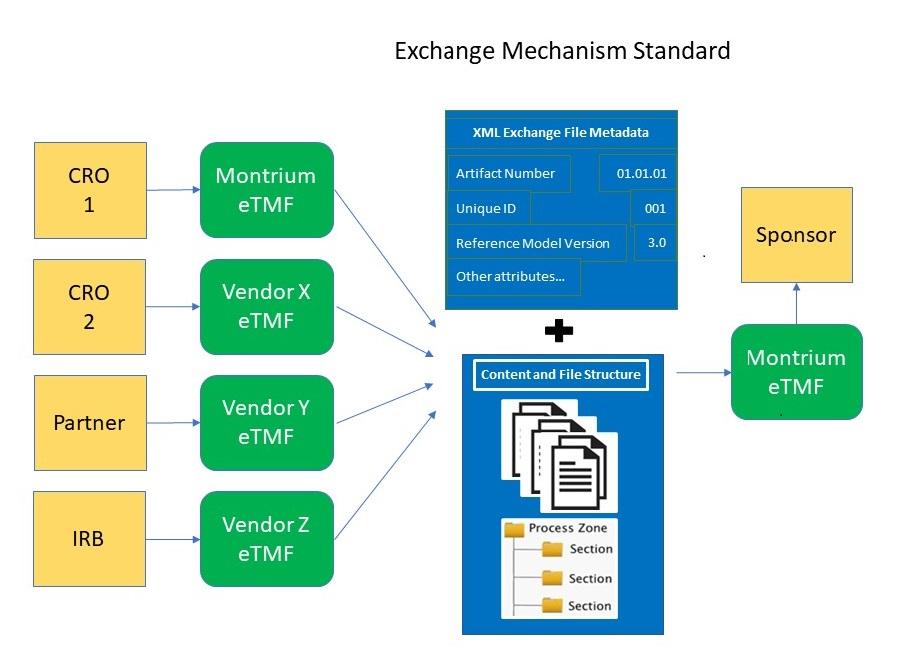
Not Just an Exchange Mechanism
EMS is not just for transferring documents between systems. It could also help improve integration across clinical and regulatory processes. An ML application that indexes documents for an eTMF could index them for other systems. If the application employs EMS to index a document, any EMS-compliant system can receive it. For example, a regulatory electronic document management system (EDMS) and an eTMF may both house copies of a study report document. If an ML application were to index the document using the EMS format, then both systems could accept it.
ML, combined with EMS, could reduce the number of TMF content exchanges. Automated indexing of different types of documents would be validated separately. Algorithms validated at high precision thresholds for some document types could run without intervention. Others validated at lower levels could suggest indexes for a user to accept or modify. TMF content exchanges would remain necessary for algorithms not validated for indexing certain types of documents. Even in these cases, EMS could still eliminate the need for mapping metadata.
Should a company train and validate a neural network in-house or outsource these activities? Companies considering the potential of ML may wish to develop in-house expertise. An important consideration is the scale required for training ML to recognize many document types. ML precision generally increases by the number and quality of examples used for training. The degree to which documents are structured consistently (standardized) also affects performance. Training a network to recognize standardized documents may be possible for some organizations. Training for highly unstructured documents (meeting minutes) requires many more examples and may be less feasible.
Some TMF service providers, including some CROs, are likely to invest in training ML models on a large scale. Such providers have large repositories of customer documents that could serve as ML training data sets. ML would help make document processing more productive for the trials they run. They could also offer ML document indexing and classification services to their customers. The sponsors they serve could benefit from pooling their trial documents into large training data sets. Sponsors who own the documents might be willing to allow service providers to use them as examples for ML training because those who acquire the resulting services would never access those documents.
Help shape the vision of EMS!
Companies can begin now to improve TMF operations through ML document classification and indexing. Combining ML with EMS could improve data integration and inspector access to trial documents. EMS helps companies avoid the non-value adding activity of mapping metadata to exchange content.
The TMF Reference Model Exchange Mechanism team is conducting a survey to understand EMS’s benefits that are most important to your company. The goal of the survey is to increase industry adoption of the standard. If you are a stakeholder in the success of your company’s TMF, consider submitting your views now at https://montrium.typeform.com/to/xsm692NG.






.png)




-1.png)